Gathering Data for Pokemon Passport Service
by William Spires
Picking my latest Project
The release of Pokémon Sword and Shield brought a new source of confusion to the Pokémon community. Rather than have all pokémon on the new games, only a select group of pokémon would make the transition. This was upsetting, but it also inspired a new question, “Where could I catch each pokémon?” I also wondered which games featured my favorite pokémon. These questions launched me into my next project.
Finding a dataset
Initially, I planned on going through each Pokémon and listing the last game you could acquire the Pokémon and the last game you could use the Pokémon as a member of your party. With 890 total Pokémon this was a monumental undertaking. To save myself time I started looking for a data source.
There are several popular sources of information on Pokémon, including PokeAPI, Serebii, and Bulbapedia. PokeAPI contains a ton of information on Pokémon, but does not have data on Pokémon game appearances. Serebii and bulbapedia both had this information, but Serebii has the information spread out over several different pages. Bulbapedia had all the information on one webpage. This web page had the exact information I wanted to use for my project. Now that I had the data the next issue was getting it in a format that programs could easily consume.
Looking into web scraping options
I wanted a data set that I could host with my applications. This would save computational resources, as an incoming request would simply have to reference the data set. I expected this data to change irregularly, so I didn’t want to scrap Bulbapedia with every request. I started looking into ways to take the data I wanted from the site. My first instinct was to try Beautiful Soup, but inspecting the HTML page convinced me that writing this code would be difficult. A friend of mine suggested looking at the IMPORTHTML feature on Google Sheets.
Google Sheets has a built-in function called IMPORTHTML. This function scans web pages for tables, and imports the information into a spreadsheet. To use IMPORTHTML go to a cell and type “=IMPORTHTML(URL ,table, the table # you’re looking for). So to scrap the table for Pokémon from the Kanto region, I typed out ‘=IMPORTHTML(“https://bulbapedia.bulbagarden.net/wiki/List_of_Pokémon_by_availability”,”table”,3)’. To retrieve the other regions I simply added 1 to the table count(tables 4, 5, 6, 7, 8, 9, 10). When I finished I had 8 tables that described the availability of each Pokémon in the series.
Struggles with IMPORTHTML
The IMPORTHTML method is a great way to quickly scrap data from a web page, but it is not without flaws. If you query the same page repeatedly, your requests might be blocked. When I was learning how IMPORTHTML works, I found myself blocked halfway through my work. I considered trying to fix this problem, but when I revisited the project the next day the block was removed. There may be a fix, but I have not found one. Another struggle is finding the right table number. If your page is well laid out, you can just count the tables. The Bulbapedia page I scraped used a table to inform the reader about changes to the page and a table for the key. I wasn’t anticipating this web design choice, so I had to experiment a little to get the table I wanted. You will encounter difficulties when using IMPORTHTML, but they are easy to overcome and the result is worth it.
Customizing the Data
Now that I had my data, I needed to transform it into a file that organized the pokemon by number and gave the reader info on the last game a pokemon was catchable in and playable in. The data set I’d pulled contained info on every game and used the key below to tell you the status of each pokemon.
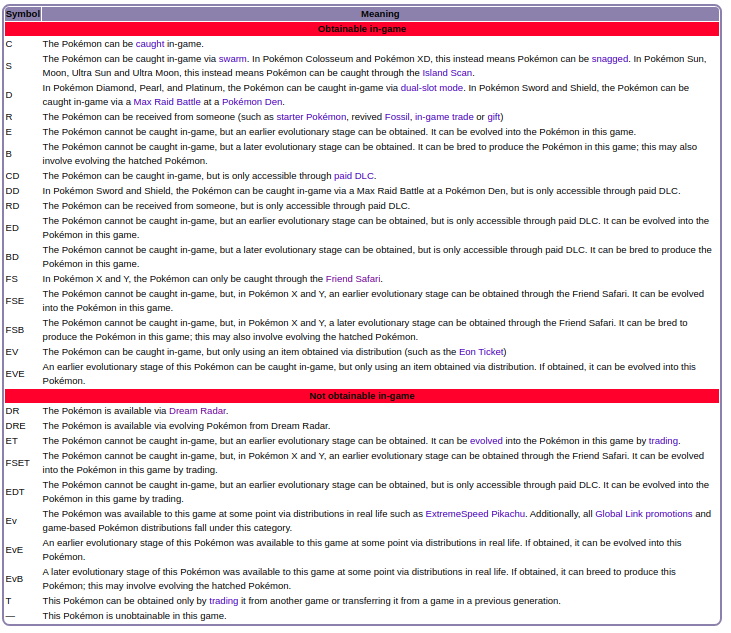
For my project, I choose to interpret C, S, D, R, E, B, FS, FSE, FSB, EV, EVE, ET, and FSET as obtainable in-game. All of these codes represented an obtaining method that is relatively easy to accomplish without the need for an event or an application that no longer exists. Additionally, if the Pokémon had any codes, then I interpreted that as the Pokémon being playable. All the codes indicate a way to get the Pokémon into a game, so if a Pokémon has a code clearly you can play with it in the game.
I merged my eight spreadsheets from the eight tables I scraped earlier. Then, I saved two copies of the spreadsheet which I labeled ‘PokeProject-Playable’ and ‘PokeProject-Obtainable’. In the ‘PokeProject-Playable’ file, I used find and replace to change all the letter codes to ‘Playable’, and kept all appearances of ‘-“ the same. In ‘PokeProject-Obtainable’ I used find and replace to change every appearance of C, S, D, R, E, B, FS, FSE, FSB, EV, EVE, ET, and FSET to ‘Obtainable. With these two spreadsheets, I was able to create a simplified CSV document. This document listed every Pokémon and the last game the Pokémon was playable and obtainable in. This was the data set I wanted for my project.
Things I Overlooked
As I began to work with this data set I realized there were some edge cases I overlooked. One major edge case I encountered was event Pokémon. Occasionally, Gamefreak will issue Pokémon through special events. These events are usually time-sensitive, so it’s possible for some Pokémon to no longer be available in a game. To handle this situation I used Serebii’s list of event Pokémon. I manually scrolled through my spreadsheet of Pokémon, focusing primarily on legendary and mythical Pokémon. Because I was focused on the last appearance of each Pokémon this process was relatively easy. However, this detail did mean that some Pokémon would be labeled as “Never Available”. Additionally, some events can be triggered through tricks or on old saves. I carefully debated each event Pokémon and I’m still considering changing the data set so it takes note of event-only Pokémon.
Another edge case I encountered was content that no longer exists or is hard to access. Friend Safari and Dream World are two examples of hard or impossible to access content. Dream World was an online companion game for Generation V Pokémon games. Players could send their Pokémon from the mainline games into Dream World. Within Dream World, you could collect items and befriend Pokémon. These befriended Pokémon can then join you in the mainline series. Dream World was shut down in early 2014. Because pokemon were no longer available through Dream World, I completely removed the Dream World column from my original spreadsheet.
Friend Safari was my other edge case. Friend Safari is a feature in Pokémon X & Y. In Kiloude City players can visit the Friend Safari. This area allows you to encounter Pokémon that are normally not available within the game. To unlock the Friend Safari you must have friends on your 3DS friend list. The 3DS is declining in use, so I wasn’t sure if I should keep these entries in my dataset. While the 3DS is slowly fading away, you don’t need active friends. You can still add friends on the 3DS platform, so players can still access the Friend Safari. Because Friend Safari only required a small amount of extra effort to access I decided to leave it in my dataset.
Looking over these edge cases helped me improve the data, making it more useful to future users. Additionally, it taught me that while scraping can provide you with a huge amount of data quickly, you may want to look over that data before immediately implementing it in a project.
Overall Impressions
Web scraping is a valuable tool for gathering data, but using python-based solutions is difficult at times. I appreciated how easy it was to use IMPORTHTML within Google Sheets. Additionally, Google Sheets made altering the data to suit my needs simple. I appreciate having access to this tool, and I plan on using it again in the future. If you’d like to find out more about my projects feel free to check out my other articles.
Subscribe via RSS